Deform360: A Massive Multi-view Visuotactile Dataset for Deformable World Models
198 daily-life deformable objects. 1,980 interactions. 41 surround-view cameras and bimanual tactile grippers — a foundation for benchmarking 2D and 3D world models on real-world deformable dynamics.
Watch it move. Could you predict the next second?
A robot that could imagine how this shirt folds would know how to act on it. Today's robots can't do this reliably — predicting deformable motion remains one of the hardest open problems in physical-world reasoning, with high-dimensional state and contact that is usually occluded. The rest of this page is about why, and what it takes to change that.
Why deformable dynamics challenge current world models
Deformable bodies — rope, cloth, plush toys — have theoretically infinite degrees of freedom, and the contact that drives their motion is frequently occluded by the gripper or the object itself. That combination is what makes the next second so hard to predict.
Two paradigms have emerged to model this: predicting dynamics in 2D pixel space (video generation) or in explicit 3D geometric space (particles & meshes). Comparing them requires diverse, large-scale, multi-view data with high-fidelity 3D annotations and tactile contact cues through occlusion.
Internet-scale pre-training captures rich appearance, yet long-horizon rollouts suffer 3D and temporal inconsistency.
Explicit geometry and structural priors support data-efficient prediction, but current learned 3D models lack comparable massive pre-training.
Existing benchmarks trade off diversity, scale, multi-view coverage, tactile sensing, and annotation fidelity—making controlled comparison difficult.
No data could settle it — so we built Deform360
Deform360 contains 215.7 cumulative multi-view hours of synchronized 41-view video and bimanual tactile recordings across 198 everyday deformable objects, paired with dense markerless 3D particle annotations.
A markerless visuotactile tracking pipeline — combining multi-view reconstruction and tactile contact signals — turns those recordings into dense particle annotations, enabling a controlled comparison of 2D video models and 3D particle models on real-world deformable dynamics, and measuring the trade-off between structural priors and scale.
A significant increase in scale and sensory richness
Every interaction is captured by a synchronized rig built for full 360° observability — multi-view coverage that substantially reduces the occlusion that limits single-view setups, complemented by tactile sensing for contact regions that remain out of camera view.
Object taxonomy — graded by material response
Varying stiffness and thickness.
Diverse textiles, airbags and thin shells.
Objects that exhibit large shape change.
Numbers on a slide are easy to claim. So don't take ours — reach in and turn the data over yourself.
Fully interactive 3D reconstructions
Click any object to load it live — orbit, zoom and pan in real 3D.

per-frame 3DGS · full set released with the dataset
How it compares
Deform360 substantially increases the scale and sensory richness of real-world deformable benchmarks: 198 objects, 41 calibrated surround views, tactile sensing, and dense markerless 3D annotations.
Per-frame geometry is only half the problem. Contact-induced motion is frequently hidden under a gripper or behind a fold—so how do we recover dense, temporally consistent 3D motion?
From raw video & touch to dense particle motion
A markerless pipeline decouples per-frame geometry from temporal tracking: 3D Gaussian Splatting recovers high-fidelity geometry each frame, 2D tracks are lifted into 3D for multi-view consistency, and tactile signals enforce physical plausibility through occlusion.
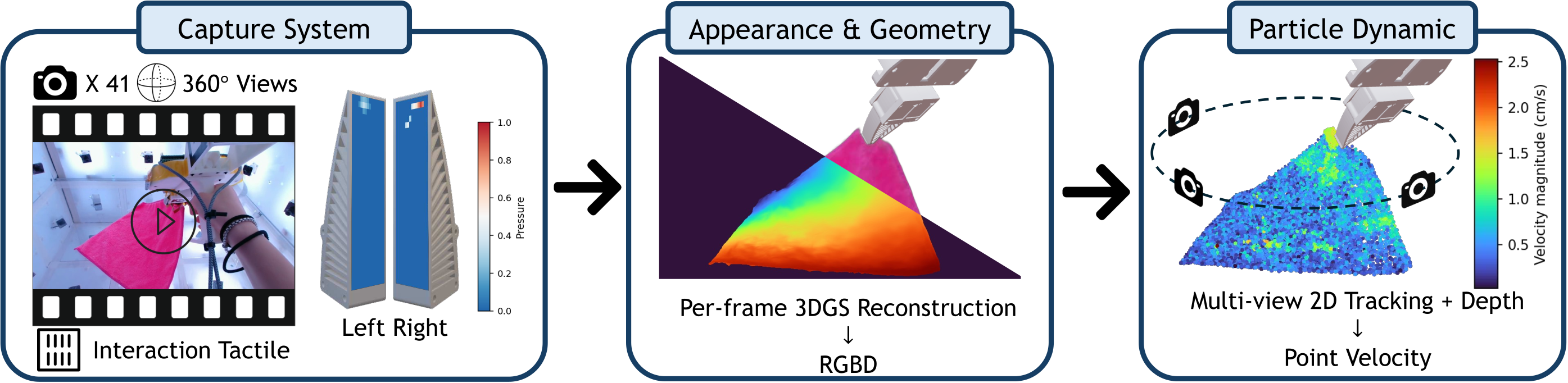
Multi-view video + tactile → per-frame 3DGS → markerless 2D tracking → 3D lifting → physics-informed optimization.
{{ p.body }}
Tactile signals through occlusion
Synchronized tactile sensors measure normal-pressure contact cues that help constrain particle motion where cameras are occluded. Tangential micro-slip remains unobserved.
With dense 3D state recovered for every frame, the dynamics come alive — explore them yourself.
Explore the reconstructions in 4D
Each sequence reconstructs both appearance (3DGS) and particle dynamics over time. Orbit, scrub, and inspect — these are live Viser viewers, not videos.
Note: for fast, stable playback in the browser, this viewer shows the Gaussian-Splatting centroids as a point cloud (rather than rendering the full splats), includes 3 of the camera views, and subsamples the tracked points whose motion trails are drawn. Click below to load the live, interactive viewer.
{{ seqReady }} · full set of 1,980 available in the release
Real-world planning
As a preliminary demonstration, a PhysTwin representation learned from Deform360 is used for model-predictive control on a different xArm robot in another lab. The planner rolls out actions that move cloth and rope toward a goal state, without fine-tuning to the new setup.
So we arrive back at the question we opened with: to predict a deformable future, should you trust pixels or particles?
2D video vs. 3D particle models
The result depends on the task and data regime. Explicit 3D priors remain effective with very little data; on held-out episodes, ParticleFormer predicts future dynamics best; on held-out objects, pretrained Cosmos delivers the strongest PSNR and LPIPS, but can drift from commanded actions.
Multi-episode future prediction
Table 4ParticleFormer leads every reported future-prediction metric; Cosmos’s appearance advantage is in reconstruction, not held-out futures. Bold = best in column.
Multi-object generalization (zero-shot)
Table 5On unseen objects, Cosmos leads PSNR and LPIPS; ParticleFormer retains the best geometric CD and track error, which are not defined for Cosmos.
Predicted futures, side by side
Compare selected model rollouts against ground truth under two distinct held-out settings: a novel object or a novel episode.
Qualitative future rollouts for the {{ qualName }} under the {{ qualSettingCaption }} setting.
Structure helps predict; pre-training helps render and transfer.
There is no universal winner. The paper’s three evaluation regimes separate data efficiency, future prediction, and zero-shot visual generalization.
PhysTwin leads the per-episode 3D benchmark. Cosmos is not reported because so little data did not support stable post-training.
Cosmos best reconstructs texture and appearance, but ParticleFormer leads every reported metric on held-out future prediction.
Cosmos leads PSNR and LPIPS; ParticleFormer retains the best geometric errors. Cosmos can still drift from commanded actions on long rollouts.
For control, explicit state still matters. Particle models expose 3D geometry for objectives such as Chamfer distance. The paper does not deploy Cosmos for MPC because cross-environment appearance shift and reward design directly in video space remain difficult.
Annotation limits. Heavy self-occlusion, highly plastic materials, and slip can still reduce tracking fidelity; the current tactile sensors measure normal pressure and do not directly observe micro-slip.
Fully open — plug and play
The Deform360 dataset and the full pipeline are open-sourced. Every stage — capture, reconstruction, perception, and the world-model baselines — is modular, so if you have a stronger perception pipeline or a better module, you can swap it in and run against the same benchmark.
Improvements are welcome — open an issue or submit a pull request to push the pipeline forward.
BibTeX
{{ bibtex }}